

Según Wikipedia, el vídeo digital es la representación de imagen en forma de datos digitales codificados. Es decir, al contrario que el vídeo analógico, que se representa y se transmite a través de procesos electromagnéticos, el vídeo digital se almacena, se transmite y se representa a través de una serie de 0 y 1 que dan lugar a un contenido audiovisual codificado en un lenguaje que hay que decodificar.
Pero, ¿cómo se procesa ese vídeo? ¿Cuáles son los efectos colaterales al crear vídeo digital? Vamos a verlo poco a poco, a través de siete preguntas. ¡Allá vamos!
1. ¿Es lo mismo un formato que un códec?
Hemos dicho que el vídeo digital está codificado. Pues aquí entran en juego dos elementos: el códec que se utiliza para almacenar y transmitir ese vídeo, es decir, el “lenguaje” que se ha usado para escribir ese “texto audiovisual”, y el formato contenedor, un recipiente en el que se aloja esa información. Esto se asemeja a un vaso. Un vaso puede agua, puede contener Fanta, zumo, té, Coca-Cola, etcétera. Pues algo así pasa con los formatos de vídeo.
Este es uno de los clásicos errores de interpretación de los formatos de vídeo digital, confundir el formato con el códec. Por ejemplo, a veces a mí me han dicho “oye, no me entregues tal proyecto en MP4, que está comprimido, se ve mal, etc.” Pero esto no tiene por qué ser así, porque la compresión y la calidad de imagen te la va a dar el códec en el que se ha grabado esa imagen.
Existen muchísimos formatos contenedores, como AVI, WEBM, MOV, MKV… aunque ahora mismo el rey es el MP4. En MP4 ahora mismo los dos códecs más famosos son el h.264 y el h.265. H.264 ofrece una compresión elevada, pero H.265 ofrece exactamente la misma calidad con la mitad de tamaño de archivo. Por cierto, que ya está la nueva especificación de h.266, que reduce a la mitad de H.265 el tamaño manteniendo la calidad.
Ahora bien, decimos que el códec es el idioma en el que está escrito este texto “audiovisual”, pero, ¿quién escribe este texto en este idioma? Aquí entran en juego los encoders, o los “escritores” que van a usar los recursos de nuestro equipo para escribir más o menos rápidamente el vídeo en este códec.
Hay muchos encoders para h.264, siendo los más utilizados ahora mismo x264, de código abierto y que utiliza la CPU de nuestra computadora, y NVIDIA NVEnc, que utiliza el chip de procesamiento gráfico, es decir, la GPU, de las tarjetas gráficas de Nvidia. Por supuesto no son los únicos, sino que hay más encoders gratuitos y comerciales en el mercado.
Para editar vídeo usamos formatos comprimidos y no comprimidos, aunque no todos funcionan por igual. Para saber cuáles son los mejores y, además, adentrarte en la edición de vídeo, te recomiendo el curso gratuito de Cortar por lo sano, en el que en 10 lecciones te explico todo lo que necesitas saber para empezar en este fascinante mundo. ¡Y con tu curso recibirás también una guía gratuita en forma de eBook!
Ahora bien, ¿qué ocurre cuando comprimimos un vídeo? Sigue leyendo…
2. ¿Qué ocurre cuando comprimimos un vídeo?
Cuando comprimimos un vídeo digital, básicamente lo que estamos haciendo es descartar información del vídeo original, usando algoritmos que realizan aproximaciones en este más o menos precisas dependiendo del caudal de datos o bitrate que le pongamos.
Estas aproximaciones se realizan de dos maneras: espacialmente, es decir, dentro de un mismo fotograma mediante los bloques CTU o macrobloques, y temporalmente, es decir, en la sucesión de fotogramas, que es la parte más interesante porque se trata de vídeo, no de una imagen estática.
Pues bien, para no extendernos mucho diremos que hay diferentes tipos de compresión entre fotogramas, siendo las más habituales la I-frame y la GOP, o Group Of Pictures. La I-frame es no predictiva y la GOP es predictiva. ¿Qué significa esto? Pues que en el caso del I-frame vamos a tener en un segundo de vídeo, 25 fotogramas a toda calidad, sin realizar ninguna aproximación de ningún tipo entre estos fotogramas.

Por el contrario, en la compresión GOP vamos a tener, en un segundo de vídeo, varios fotogramas clave, llamados keyframes, entre los que se interpolan fotogramas predictivos. De hecho, esos fotogramas realmente no son fotogramas, sino trocitos de código que dicen “creo que este píxel va aquí, creo que este píxel va allá”. Con esto estamos ahorrando una enorme cantidad de espacio, por lo que la compresión GOP es la que utilizan códecs como el h.264. En el caso del I-frame es usado en códecs como ProRes, de ahí la gran cantidad de espacio que se necesita.
Y exactamente lo mismo ocurre cuando grabamos vídeo, y es muy común encontrar en nuestras cámaras dos modos de compresión: All-Intra por un lado y GOP. En el caso de All-Intra se realizará un proceso similar al I-frame, aplicando, como su nombre indica, una compresión solo dentro de cada frame. Hace un “all in” dentro del frame, no entre frames.
Y esto nos lleva a la siguiente pregunta.
3. ¿Por qué “late” un vídeo comprimido?
Seguro que alguna vez te has dado cuenta, cuando estás viendo una escena estática en una película comprimida, que a veces se producen como “latidos” en la imagen a un ritmo constante.
Antes hemos dicho que usamos fotogramas clave para comprimir temporalmente. Pues bien, cuando codificamos, colocamos esos fotogramas clave en puntos fijos para usarlos de referencia. Es decir, el encoder lo que hace es refrescar esa imagen de referencia según el intervalo de keyframes que tenga asignada la compresión.
Así que ya sabes por qué tiene ese efecto tan extraño esa película comprimida que te has descargado de… tú ya sabes dónde.
4. ¿Por qué una GPU es más rápida que una CPU para h.264?
Antes hemos dicho que podemos usar nuestra GPU para editar vídeo. De hecho, en muchos casos es recomendable porque la velocidad de procesamiento es mucho mayor. Pero, ¿por qué?
Pues básicamente porque las GPU modernas tienen una parte del chip dedicada a la codificación en h.264 y h.265. Con esto estamos liberando de trabajo pesado a la CPU, que cuando comprime o descomprime vídeo usando estos códecs toman transistores del procesador para realizar esta tarea, transistores que pueden servir para cualquier tarea y por lo tanto no está especialmente optimizada para nada. Son el sistema operativo y el encoder los que tienen que realizar una abstracción. Es como si le dijeran a la CPU: “oye, ahora tú te vas a convertir en un compresor de vídeo”.
Por el contrario, una GPU ya está especializada en el procesamiento gráfico. Si, además, tenemos una parte que ya sabe que se va a dedicar a comprimir vídeo, tenemos una auténtica bestia de la compresión en este códec.
5. ¿Qué es el 4:2:2 o 4:2:0?
A veces se puede dar el caso de que estés utilizando formatos intermedios, también llamados mezzanine, como pueden ser GoPro Cineform, DNxHD, etc., y te digan “procura que esté a 4:2:2”. Y tú te quedas, EEINNNN? ¿Qué significa 4:2:2?
Para explicar esto tenemos que entender el concepto de “submuestro de crominancia”. Vayamos por partes. El ojo humano tiene conos y bastones. Los conos son células que nos permiten distinguir colores y los bastones nos permiten distinguir cambios de luminosidad. Luz y color, ya tenemos los elementos fundamentales de una imagen.
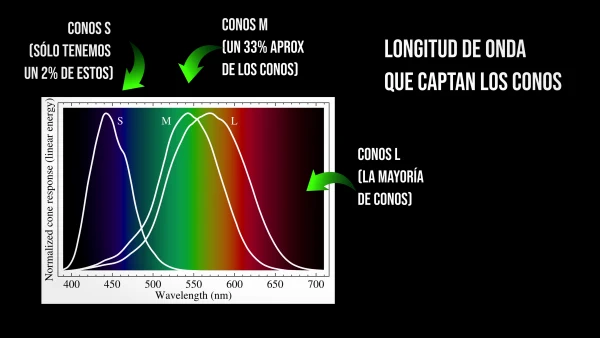
Resulta que el ojo humano, por razones adaptativas, es más diestro distinguiendo cambios de luminosidad que cambios en el color, sobre todo del rojo y del azul.
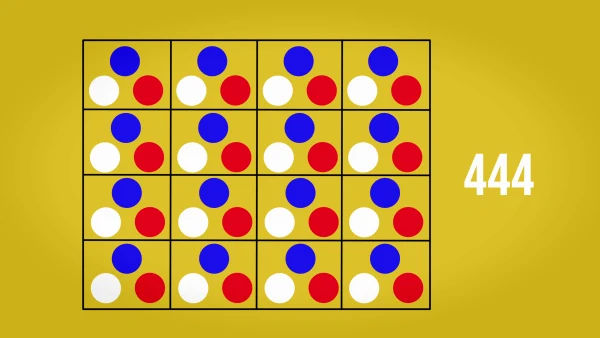
En los años 50 del siglo XX, los ingenieros de RCA se dieron cuenta de que, eliminando información del rojo y del azul, se reducía la señal de vídeo sin afectar a los colores que percibimos. Esto, traducido al vídeo digital, es lo que determina que tengamos señales a 4:4:4, 4:2:2 y 4:2:0 normalmente.
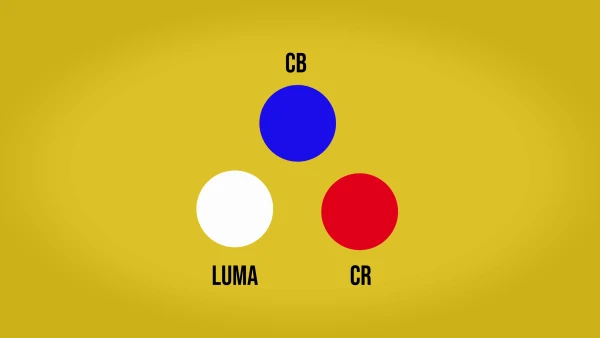
Cada píxel en vídeo tiene un valor Y (luminancia), un valor Cb (crominancia Azul) y Cr (crominancia Rojo). Si creamos una matriz de 4 x 4 píxeles manteniendo todos estos valores, estaremos construyendo una imagen con un 4:4:4 perfecto.
Sin embargo, aquí estamos por así decirlo malgastando información de color y, por ende, de almacenamiento o ancho de banda, ya que, como hemos dicho, el ojo humano no es capaz de distinguir todos los colores con la misma destreza. Así que, para aligerar el tamaño del vídeo o el ancho de banda que ocupa, eliminamos exactamente la mitad de la información del rojo y del azul, quedando en la matriz 8 píxeles con toda la información y 8 píxeles sin azul ni rojo, de forma que luego se hará una media, dicho muy rápidamente, de los colores que faltan según la información que ya tenemos de los píxeles adyacentes. Esto es el submuestreo a 4:2:2.
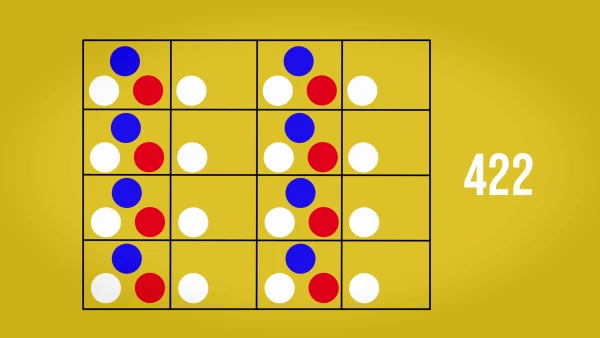
Por su parte, en una señal 4:2:0, hay varias maneras de conseguirlo porque hay más posibilidades para hacer el reparto de colores en la matriz, pero lo más común es dejar información de un color en la mitad de los píxeles de la primera y tercera fila e información del otro color en la mitad de los píxeles de la segunda y la cuarta fila.
Esto se traduce en una resolución de color menor y por tanto, en un vídeo más liviano. 4:2:0 es el submuestreo que usan formatos como el H.264.
6. ¿Para qué sirve hacer varias pasadas para comprimir vídeo?
Sobre todo antes, con códecs más antiguos, realizar más de una pasada era conveniente si teníamos que ajustar el vídeo en un tamaño de archivo que fuera fijo. Por ejemplo, para un DVD teníamos 4.7 gigabytes de tamaño máximo que podía ocupar con nuestra película.
Hoy en día, aunque en programas como Handbrake podemos realizar varias pasadas, encoders como x264 y NVEnc han mejorado tanto que ya casi no se necesitan varias pasadas, máxime en estos tiempos en los que los procesadores son más rápidos que nunca y los límites de tamaño son más laxos.
7. ¿Cuál es el futuro del vídeo digital?
Para llegar hasta aquí hemos recorrido un largo camino. Los más veteranos recordarán códecs como Divx o Xvid y programas como Gordian Knot, Canopus Procoder o CloneDVD para comprimir vídeos y dejarlos listos para su almacenamiento en CD o DVD. Para conseguir buena calidad en un tamaño comedido a menudo era necesario pelearse con los ajustes… y a veces podía no salir bien.
Hoy en día, gracias a programas como Handbrake y códecs como los mencionados, tenemos las herramientas necesarias para lo que requiere el vídeo hoy en día: compresión y velocidad de procesamiento para transmisión en tiempo real. Pero esa transmisión en tiempo real requiere de un ancho de banda que siempre puede optimizarse.
Para ello han nacido códecs como el VP9, desarrollado por Google, y AV1, creado por un consorcio de empresas entre las que están la misma Google, Netflix, Apple o Amazon. Ambos son de código abierto, y, especialmente el segundo, es el candidato más firme para imponerse en el futuro porque ofrece mayor calidad que VP9. Pero, ¿por qué hay empresas comerciales desarrollando un códec libre y gratuito? Por la sencilla razón de que son estas empresas las primeras interesadas en ofrecer vídeo a la máxima calidad ocupando el menor ancho de banda posible. Un vídeo más pequeño implica menos costes de transmisión y almacenamiento.
A día de hoy, de AV1 el encoder más avanzado es SVT-AV1, impulsado por Intel y Netflix y que va mejorando casi cada día gracias a la potente comunidad que tiene detrás. Sin duda, el futuro del mundo audiovisual pasa por soluciones abiertas como esta, de las que todos nos veremos beneficiados.
Adquiere las herramientas de trabajo de Creatubers
Equípate para tu proyecto creativo y me ayudarás con una pequeña comisión de afiliado. No pagarás de más, sino que los proveedores dejarán de recibir una pequeña parte para dársela a Creatubers.
Todos los cursos incluidos

1 comentarios en "7 curiosidades sobre el vídeo digital"